@inproceedings{minilong,title={MiniLongBench: The Low-cost Long Context Understanding Benchmark for LLMs},author={Huang, Zhongzhan and Ling, Guoming and Zhong, Shanshan and Wu, Hefeng and Lin, Liang},booktitle={The Annual Meeting of the Association for Computational Linguistics (<strong>ACL</strong> <strong style="color:red;">Outstanding Paper Award</strong>)},year={2025}}
EMNLP’25
Routereval: A Comprehensive Benchmark for Routing LLMs to Explore Model-level Scaling Up
Zhongzhan Huang, Guoming Ling, Yupei Lin, Yandong Chen, Shanshan Zhong, Hefeng Wu, and L. Lin
In The Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
@inproceedings{router,title={Routereval: A Comprehensive Benchmark for Routing LLMs to Explore Model-level Scaling Up},author={Huang, Zhongzhan and Ling, Guoming and and Lin, Yupei and Chen, Yandong and Zhong, Shanshan and Wu, Hefeng and Lin, L.},booktitle={The Conference on Empirical Methods in Natural Language Processing (<strong>EMNLP</strong>)},year={2025}}
IEEE TPAMI
A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models
Zhongzhan Huang, Shanshan Zhong, Pan Zhou, Shanghua Gao, Zitnik Marinka, and Liang Lin
In IEEE Transactions on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 2025
@inproceedings{pami,title={A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models},author={Huang, Zhongzhan and Zhong, Shanshan and Zhou, Pan and Gao, Shanghua and Marinka, Zitnik and Lin, Liang},booktitle={IEEE Transactions on Pattern Analysis and Machine Intelligence (<strong>IEEE TPAMI</strong>)},year={2025}}
2024
IEEE TNNLS
Continuous Value Assignment: A Doubly Robust Data Augmentation for Off-Policy Learning
Junfan Lin, Zhongzhan Huang, Keze Wang, Lingbo Liu, and Liang Lin
In IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2024
@inproceedings{linContinuousValue,title={Continuous Value Assignment: A Doubly Robust Data Augmentation for Off-Policy Learning},author={Lin, Junfan and Huang, Zhongzhan and Wang, Keze and Liu, Lingbo and Lin, Liang},booktitle={IEEE Transactions on Neural Networks and Learning Systems (<strong>TNNLS</strong>)},year={2024}}
@inproceedings{asr,title={ASR: Stripe Observation Guided Inference Cost-free Attention Mechanism},author={Huang, Zhongzhan and Zhong, Shanshan and Wen, Wushao and Qin, Jinghui and Lin, Liang},booktitle={The European Conference on Computer Vision (<strong>ECCV</strong>)},year={2024}}
IEEE TASLP
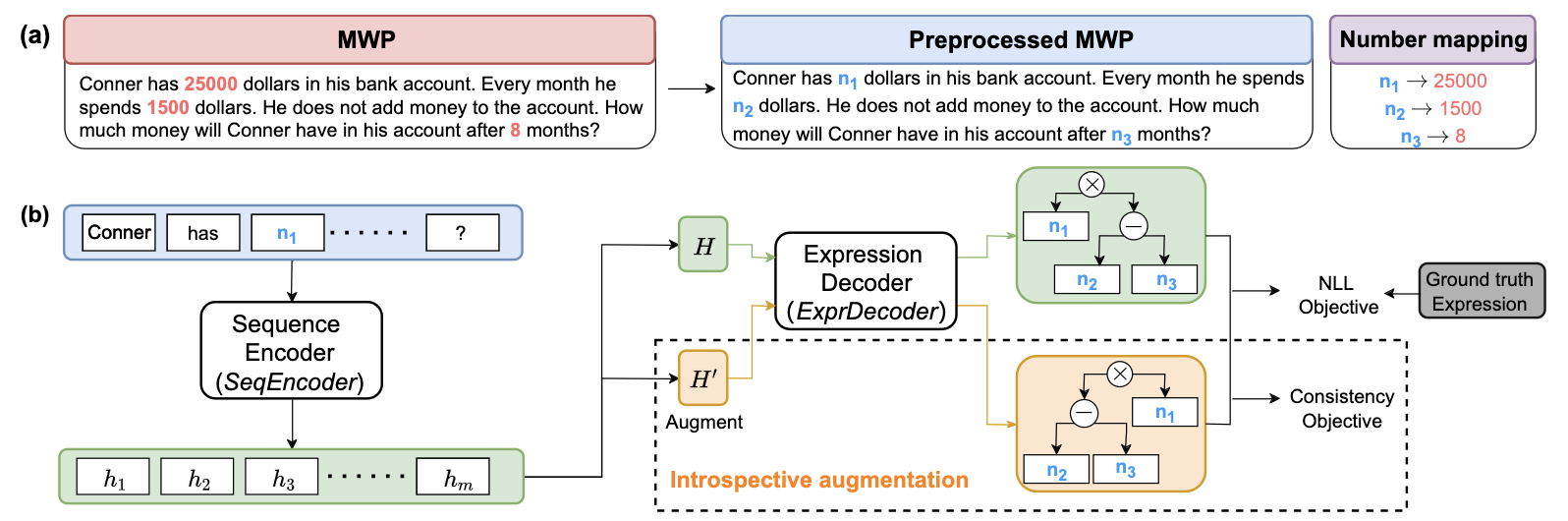
MVT: An Introspective Data Augmentation Method for Training Math Word Problem Solvers
Jinghui Qin, Zhongzhan Huang, Ying Zeng, and Liang Lin
In IEEE Transactions on Audio, Speech and Language Processing (TALSP), 2024
@inproceedings{mvt,title={MVT: An Introspective Data Augmentation Method for Training Math Word Problem Solvers},author={Qin, Jinghui and Huang, Zhongzhan and Zeng, Ying and Lin, Liang},booktitle={IEEE Transactions on Audio, Speech and Language Processing (<strong>TALSP</strong>)},year={2024}}
ICML’24
AttNS: Attention-Inspired Numerical Solving For Limited Data Scenarios
Zhongzhan Huang, Mingfu Liang, Shanshan Zhong, and Liang Lin
In The International Conference on Machine Learning (ICML), 2024
@inproceedings{AttSolver1,title={AttNS: Attention-Inspired Numerical Solving For Limited Data Scenarios},author={Huang, Zhongzhan and Liang, Mingfu and Zhong, Shanshan and Lin, Liang},booktitle={The International Conference on Machine Learning (<strong>ICML</strong>)},year={2024}}
ICME’24
The Lottery Ticket Hypothesis for Self-attention in Convolutional Neural Network
Zhongzhan Huang, Senwei Liang, Mingfu Liang, Wei He, Haizhao Yang, and Liang Lin
In IEEE International Conference on Multimedia & Expo (ICMEOral), 2024
@inproceedings{huang2022lottery,title={The Lottery Ticket Hypothesis for Self-attention in Convolutional Neural Network},author={Huang, Zhongzhan and Liang, Senwei and Liang, Mingfu and He, Wei and Yang, Haizhao and Lin, Liang},booktitle={IEEE International Conference on Multimedia & Expo (<strong>ICME</strong> <strong style="color:red;">Oral</strong>)},year={2024},}
CVPR’24
Let’s Think Outside the Box: Exploring Leap-of-Thought in LLMs with Creative Humor Generation
Shanshan Zhong, (co-first) Zhongzhan Huang, Shanghua Gao, Wushao Wen, Liang Lin, Marinka Zitnik, and Pan Zhou
In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
@inproceedings{scale,title={Let’s Think Outside the Box: Exploring Leap-of-Thought in LLMs with Creative Humor Generation},author={Zhong, Shanshan and Huang, (co-first) Zhongzhan and Gao, Shanghua and Wen, Wushao and Lin, Liang and Zitnik, Marinka and Zhou, Pan},booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition (<strong>CVPR</strong>)},year={2024},}
WWW’24
Mirror Gradient: Towards Robust Multimodal Recommender Systems via Exploring Flat Local Minima
Shanshan Zhong, (co-first) Zhongzhan Huang, Daifeng Li, Wushao Wen, Jinghui Qin, and Liang Lin
In International World Wide Web Conference (WWW), 2024
@inproceedings{mg,title={Mirror Gradient: Towards Robust Multimodal Recommender Systems via Exploring Flat Local Minima},author={Zhong, Shanshan and Huang, (co-first) Zhongzhan and Li, Daifeng and Wen, Wushao and Qin, Jinghui and Lin, Liang},booktitle={International World Wide Web Conference (<strong>WWW</strong>)},year={2024}}
2023
NeurIPS’23
ScaleLong: Towards More Stable Training of Diffusion Model via Scaling Network Long Skip Connection
Zhongzhan Huang, Pan Zhou, Shuicheng Yan, and Liang Lin
In The Conference on Neural Information Processing Systems (NeurIPS), 2023
@inproceedings{scalf,title={ScaleLong: Towards More Stable Training of Diffusion Model via Scaling Network Long Skip Connection},author={Huang, Zhongzhan and Zhou, Pan and Yan, Shuicheng and Lin, Liang},booktitle={The Conference on Neural Information Processing Systems (<strong>NeurIPS</strong>)},year={2023},}
Sci. Reports
On Fast Simulation of Dynamical System with Neural Vector Enhanced Numerical Solver
Zhongzhan Huang, Senwei Liang, Hong Zhang, Haizhao Yang, and Liang Lin
@inproceedings{huang2022accelerating,title={On Fast Simulation of Dynamical System with Neural Vector Enhanced Numerical Solver},author={Huang, Zhongzhan and Liang, Senwei and Zhang, Hong and Yang, Haizhao and Lin, Liang},booktitle={Scientific Reports (<strong>Sci. Reports</strong>)},year={2023}}
ACM MM’23
SUR-adapter: Enhancing text-to-image pre-trained diffusion models with large language models
Shanshan Zhong, (co-first) Zhongzhan Huang, Wushao Wen, Jinghui Qin, and Liang Lin
In 31th ACM International Conference on Multimedia (ACM MM Oral), 2023
@inproceedings{zhong2023adapter,title={SUR-adapter: Enhancing text-to-image pre-trained diffusion models with large language models},author={Zhong, Shanshan and Huang, (co-first) Zhongzhan and Wen, Wushao and Qin, Jinghui and Lin, Liang},booktitle={31th ACM International Conference on Multimedia (<strong>ACM MM </strong> <strong style="color:red;">Oral</strong>)},year={2023},organization={ACM Press}}
ICCV’23
Understanding Self-attention Mechanism via Dynamical System Perspective
Zhongzhan Huang, Mingfu Liang, Jinghui Qin, Shanshan Zhong, and Liang Lin
In The IEEE/CVF International Conference on Computer Vision (ICCV), 2023
@inproceedings{huang2023understanding,title={Understanding Self-attention Mechanism via Dynamical System Perspective},author={Huang, Zhongzhan and Liang, Mingfu and Qin, Jinghui and Zhong, Shanshan and Lin, Liang},booktitle={The IEEE/CVF International Conference on Computer Vision (<strong>ICCV</strong>)},year={2023}}
Neurocomp.
ESA: Excitation-Switchable Attention for convolutional neural networks
@inproceedings{zhong2023esa,title={ESA: Excitation-Switchable Attention for convolutional neural networks},author={Zhong, Shanshan and Huang, Zhongzhan and Wen, Wushao and Yang, Zhijing and Qin, Jinghui},booktitle={Neurocomputing (<strong>Neurocomp.</strong>)},pages={126706},year={2023},publisher={Elsevier}}
ICME’23
LSAS: Lightweight Sub-attention Strategy for Alleviating Attention Bias Problem
@inproceedings{zhong2023lsas,title={LSAS: Lightweight Sub-attention Strategy for Alleviating Attention Bias Problem},author={Zhong, Shanshan and Wen, Wushao and Qin, Jinghui and Chen, Qiangpu and Huang, Zhongzhan},booktitle={IEEE International Conference on Multimedia & Expo (<strong>ICME</strong> <strong style="color:red;">Oral</strong>)},year={2023}}
2022
EMNLP’22
CEM: Machine-Human Chatting Handoff via Causal-Enhance Module
Shanshan Zhong, Jinghui Qin, Zhongzhan Huang, and Daifeng Li
In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022
@inproceedings{zhong2022cem,title={CEM: Machine-Human Chatting Handoff via Causal-Enhance Module},author={Zhong, Shanshan and Qin, Jinghui and Huang, Zhongzhan and Li, Daifeng},booktitle={Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (<strong>EMNLP</strong>)},pages={3242--3253},year={2022}}
ICLR’22
Stiffness-aware neural network for learning Hamiltonian systems
Senwei Liang, Zhongzhan Huang, and Hong Zhang
In International Conference on Learning Representations (ICLR), 2022
@inproceedings{liang2021stiffness,title={Stiffness-aware neural network for learning Hamiltonian systems},author={Liang, Senwei and Huang, Zhongzhan and Zhang, Hong},booktitle={International Conference on Learning Representations (<strong>ICLR</strong>)},year={2022}}
2021
NeurIPS’21
Rethinking the Pruning Criteria for Convolutional Neural Network
Zhongzhan Huang, Wenqi Shao, Xinjiang Wang, Liang Lin, and Ping Luo
In The Conference on Neural Information Processing Systems (NeurIPS), 2021
@inproceedings{huang2021convolution,title={Rethinking the Pruning Criteria for Convolutional Neural Network},author={Huang, Zhongzhan and Shao, Wenqi and Wang, Xinjiang and Lin, Liang and Luo, Ping},booktitle={The Conference on Neural Information Processing Systems (<strong>NeurIPS</strong>)},year={2021},}
ICANN’21
Blending Pruning Criteria for Convolutional Neural Networks
Wei He, (co-first) Zhongzhan Huang, Mingfu Liang, Senwei Liang, and Haizhao Yang
In International Conference on Artificial Neural Networks (ICANN), 2021
@inproceedings{he2021blending,title={Blending Pruning Criteria for Convolutional Neural Networks},author={He, Wei and Huang, (co-first) Zhongzhan and Liang, Mingfu and Liang, Senwei and Yang, Haizhao},booktitle={International Conference on Artificial Neural Networks (<strong>ICANN</strong>)},year={2021},}
ICRA’21
Continuous Transition: Improving Sample Efficiency for Continuous Control Problems via MixUp
Junfan Lin, Zhongzhan Huang, Keze Wang, Xiaodan Liang, Weiwei Chen, and Liang Lin
In IEEE International Conference on Robotics and Automation (ICRA), 2021
@inproceedings{lin2020continuous,title={Continuous Transition: Improving Sample Efficiency for Continuous Control Problems via MixUp},author={Lin, Junfan and Huang, Zhongzhan and Wang, Keze and Liang, Xiaodan and Chen, Weiwei and Lin, Liang},year={2021},booktitle={IEEE International Conference on Robotics and Automation (<strong>ICRA</strong>)}}
2020
AAAI’20
Instance enhancement batch normalization: An adaptive regulator of batch noise
Senwei Liang, (co-first) Zhongzhan Huang, Mingfu Liang, and Haizhao Yang
In The AAAI Conference on Artificial Intelligence (AAAI), 2020
@inproceedings{liang2020instance,title={Instance enhancement batch normalization: An adaptive regulator of batch noise},author={Liang, Senwei and Huang, (co-first) Zhongzhan and Liang, Mingfu and Yang, Haizhao},booktitle={The AAAI Conference on Artificial Intelligence (<strong>AAAI</strong>)},year={2020}}
AAAI’20
DIANet: Dense-and-implicit attention network
Zhongzhan Huang, Senwei Liang, Mingfu Liang, and Haizhao Yang
In The AAAI Conference on Artificial Intelligence (AAAI), 2020
@inproceedings{huang2020dianet,title={DIANet: Dense-and-implicit attention network},author={Huang, Zhongzhan and Liang, Senwei and Liang, Mingfu and Yang, Haizhao},booktitle={The AAAI Conference on Artificial Intelligence (<strong>AAAI</strong>)},year={2020}}
preprint
Arxiv
A Generic Shared Attention Mechanism for Various Backbone Neural Networks
Zhongzhan Huang, Senwei Liang, Mingfu Liang, and Liang Lin
@inproceedings{huang2022layer,title={A Generic Shared Attention Mechanism for Various Backbone Neural Networks},author={Huang, Zhongzhan and Liang, Senwei and Liang, Mingfu and Lin, Liang},booktitle={arXiv preprint (in submission)},year={preprint}}
Arxiv
Efficient Attention Network: Accelerate Attention by Searching Where to Plug
Zhongzhan Huang, Senwei Liang, Mingfu Liang, Wei He, and Haizhao Yang
@inproceedings{huang2020efficient,title={Efficient Attention Network: Accelerate Attention by Searching Where to Plug},author={Huang, Zhongzhan and Liang, Senwei and Liang, Mingfu and He, Wei and Yang, Haizhao},booktitle={arXiv preprint (in submission)},year={preprint}}
Arxiv
AlterSGD: Finding Flat Minima for Continual Learning by Alternative Training
Zhongzhan Huang, Mingfu Liang, Senwei Liang, and Wei He
@inproceedings{huang2021altersgd,title={AlterSGD: Finding Flat Minima for Continual Learning by Alternative Training},author={Huang, Zhongzhan and Liang, Mingfu and Liang, Senwei and He, Wei},booktitle={arXiv preprint (in submission)},year={preprint}}
Arxiv
Deepening Neural Networks Implicitly and Locally via Recurrent Attention Strategy
Shanshan Zhong, Zhongzhan Huang, Wushao Wen, and Liang Lin
@inproceedings{ram,title={Deepening Neural Networks Implicitly and Locally via Recurrent Attention Strategy},author={Zhong, Shanshan and Huang, Zhongzhan and Wen, Wushao and Lin, Liang},booktitle={arXiv preprint (in submission)},year={preprint}}